![]() Edificio CIBA
Edificio CIBA
Avda. San Juan Bosco, 13
50009 Zaragoza
En esta sección se describe la metodología empleada en el estudio de las variaciones en la práctica médica y en los Atlas publicados. Además en cada uno de los Atlas de Variaciones en la Práctica Médica (Atlas VPM) publicados se encuentra la descripción de la metodología empleada en ese atlas en concreto.
¿Cuál es el objetivo de AtlasVPM?
Análisis de variaciones sistemáticas de la práctica médica
AtlasVPM aborda el análisis de las variaciones sistemáticas de la práctica médica (VPM) desde la perspectiva de la organización territorial y administrativa del sistema sanitario español (Sistema Nacional de Salud), y del análisis del desempeño de los proveedores de asistencia sanitaria (principalmente, hospitales).
Este tipo de análisis se enmarcan dentro de la investigación en políticas y servicios sanitarios, y se usan para evaluar la experiencia de cuidados y resultados en salud de la población que reside en una determinada área geográfica o que utiliza un determinado recurso sanitario (e.g., hospital) con el objetivo de medir la variabilidad observada en la práctica médica entre distintas unidades de análisis (i.e., entre distintas áreas, regiones o entre hospitales dentro y fuera de las mismas regiones).
AtlasVPM usa principalmente métodos y técnicas de análisis espacial, cómo el análisis de área pequeña (small area estimation) para el análisis por área geográfica y modelos de regresión generalizados lineales multinivel para la estimación de indicadores de utilización, calidad o resultados en salud y ajuste de riesgos.
Adicionalmente, AtlasVPM requiere del uso de otros métodos y técnicas de aprendizaje estadístico como el análisis de conglomerados (cluster analysis), o técnicas de reducción de dimensionalidad (i.e., análisis de componentes principales o análisis factorial) con objeto de segmentar o clasificar las unidades de análisis en grupos comparables, o también para sintetizar la información relevante en componentes o parámetros relevantes con el fin de incrementar la capacidad explicativa de los modelos utilizados y minimizar el impacto de la variación aleatoria (no sistemática) en los indicadores estudiados.
¿Qué son y cómo se estudian las variaciones injustificadas de la práctica médica?
Variaciones injustificadas de la práctica médica
AtlasVPM estudia tasas ajustadas de distintos indicadores y las compara para caracterizar las diferencias observadas, descartando que estas atiendan a factores epidemiológicos (i.e., sexo, edad, carga de enfermedad) o de necesidad de cuidados (i.e., prevalencia de enfermedad) de la población, que podrían justificar estas diferencias, para enfocarse en aquellas discrepancias que no pueden ser explicadas por estos motivos. Cuando estas diferencias injustificadas se observan de forma sistemática se habla de variaciones injustificadas de la práctica médica, y merecen una atención especial porque pueden estar señalando oportunidades de mejora en la organización y la prestación de cuidados sanitarios.
AtlasVPM estudia las variaciones en la práctica médica a través de la evaluación de indicadores de utilización, accesibilidad, equidad, seguridad o calidad de la asistencia sanitaria o de medición de resultados en salud. En general, estos indicadores se calculan a partir de una selección de casos de interés (i.e., casos del fenómeno o suceso que se desear medir – ingreso hospitalario por alguna causa, intervención quirúrgica, prueba diagnóstica, etc.) en un periodo de tiempo determinado. El número de casos seleccionados con la característica de interés en el periodo de estudio se corresponde habitualmente con el numerador. Este numerador se contrasta con la población de la unidad de análisis de la que se extrae la selección de casos (i.e., típicamente el área sanitaria o la zona básica de salud, como demarcación administrativa de gestión de los servicios sanitarios en el análisis geográfico o la población atendida en el análisis por proveedor), siendo esta población el denominador. Estos elementos –numerador y denominador- permiten calcular una tasa media del suceso de interés en el periodo de estudio.
El cálculo de los indicadores sobre los que se evalúa la variación geográfica vendría definido por la fórmula:
(Casos seleccionados en un área sanitaria en el periodo de estudio) / (Población total del área sanitaria en el periodo de estudio)
= Tasa cruda de cada área sanitaria
El cálculo de los indicadores sobre los que se evalúa el desempeño por proveedor vendría definido por la fórmula:
(Casos seleccionados en relación a un indicadoratendidos por un proveedor sanitario (hospital) en el periodo de estudio) / (Población atendida en relación a ese indicador por ese proveedor (hosptial) en el periodo de estudio)
= Tasa cruda por proveedor (hospital)
A partir de la estimación de esta tasa media para cada unidad de análisis (equivalente a una incidencia acumulada en el periodo de estudio, si el número de casos de interés (i.e., sucesos, intervenciones, diagnósticos, etc.) y personas fuera equiparable se utilizan fundamentalmente tres vías de análisis:
– Describir y comparar las tasas ajustadas por diversos factores para cada una de las diversas áreas geográficas y valorar si la “incidencia acumulada” de un determinado indicador (caso de interés) es mayor en unas que en otras. Para poder realizar esta comparación con cierto rigor metodológico es necesario asegurarse de que las distintas unidades de análisis son comparables entre sí, para lo que se requiere del ajuste de las tasas (i.e., ajuste de riesgo de la población expuesta por carga de enfermedad) y su estandarización por edad y sexo (utilizando una estandarización directa) o utilizando razones de hospitalización (estandarización indirecta).
– Analizar la variabilidad mediante la estimación y comparación de estadísticos desarrollados para el análisis de áreas pequeñas (small area estimation).
– Realizar una serie de análisis secundarios, de tipo ecológico, para valorar si existe algún tipo de asociación entre las tasas y algunas variables de la oferta (i.e., camas, horas de quirófanos, personal sanitario), de la demanda (i.e., privación, distancia, morbilidad) u otras.
¿Cuáles son las unidades de análisis de AtlasVPM?
Los Atlas de variaciones de la práctica médica recogen principalmente dos tipos de análisis, véase a) un análisis geográfico, basado en:
Zonas básicas de salud (ZBS)
La zona básica de salud hace referencia al área geográfica-administrativa de referencia para la provisión de servicios sanitarios de atención primaria por parte de un equipo de atención primaria.
Áreas sanitarias (AS)
El área sanitaria representa un nivel organizativo superior a la zona básica de salud, en la que se integran la provisión de los servicios sanitarios de atención primaria, con la atención especializada ambulatoria y la atención hospitalaria.
;y, b) análisis hospitalario basado en:
Los centros hospitalarios en régimen de internamiento de agudos con actividad asistencial financiada públicamente, se consideran como unidad de provisión de cuidados secundarios, especialmente en la provisión de intervenciones quirúrgicas y los cuidados derivados de estas, pero también de intervenciones diagnósticas especializadas, etc.
En los Atlas se representan geográficamente las zonas básicas de salud, áreas sanitarias actuales de residencia que responden a la organización territorial establecida por las respectivas administraciones sanitarias de las 17 CCAA, cubriendo todo el territorio nacional, exceptuando las ciudades autónomas de Ceuta y Melilla. También se representan geográficamente en determinados indicadores las zonas básicas de salud y los centros hospitalarios mediante geolocalización
El área sanitaria representa un proveedor integrado de servicios que engloba atención primaria, atención especializada ambulatoria y atención hospitalaria en el contexto del SNS español, mientras que la zona básica de salud sería el lugar de prestación de servicios de atención primaria.
Para determinados tipos de indicadores, fundamentalmente de seguridad y calidad, se evalúa el desempeño de los centros hospitalarios con actividad pública.
¿Qué fuentes de información utiliza AtlasVPM?
Numerador: número de casos.
En los indicadores que miden actividad hospitalaria, la fuente de información para la extracción de casos es el Conjunto Mínimo de Datos Básicos (CMBD) al alta hospitalaria y los registros de Cirugía Mayor Ambulatoria (CMA) de las 17 Comunidades Autónomas (CCAA) que conforman el Sistema Nacional de Salud (SNS).
Denominador: la población a riesgo
La población general se extrae de los padrones municipales actualizados y centralizados por el Instituto Nacional de Estadística (INE). Estas poblaciones censales se desagregan en 18 grupos de edad y sexo, y se distribuyen en los mapas sanitarios de cada comunidad autónoma, para reconstruir las poblaciones de cada área sanitaria y/o cada zona básica de salud.
En caso de análisis hospitalario, los casos del denominador se extraen del CMBD de las 17 CCAA, de manera análoga a los casos del numerador.
La fuente de información para la extracción de casos es el Conjunto Mínimo de Datos Básicos (CMBD) al alta hospitalaria y los registros de Cirugía Mayor Ambulatoria (CMA) de las 17 Comunidades Autónomas (CCAA) que conforman el Sistema Nacional de Salud (SNS).
Del CMBD y registros de CMA se obtiene la información clínica (motivos de ingresos, otros diagnósticos y procedimientos quirúrgicos) y administrativa (edad, sexo y residencia) referida a cada episodio de atención. Los diagnósticos y procedimientos contenidos en ambos registros están codificados siguiendo la Clasificación Internacional de Enfermedades 9ª revisión Modificación Clínica (ES-CIE9-MC) y a partir de enero del año 2016, la Clasificación Internacional de Enfermedades 10ª revisión (ES-CIE10-MC).
En el caso de indicadores que miden procesos y resultados de Atención Primaria, los datos se extraen de los sistemas de información de atención primaria de cada una de las CCAA.
Los datos de identificación de paciente y copago se extraen del sistema de información de tarjeta sanitaria.
El denominador: la población a riesgo.
La población general se extrae de los padrones municipales actualizados y centralizados por el Instituto Nacional de Estadística (INE). Estas poblaciones censales se desagregan en 18 grupos de edad y sexo, y se distribuyen en los mapas sanitarios de cada comunidad autónoma, para reconstruir las poblaciones de cada área sanitaria y/o cada zona básica de salud.
Aunque la amplia cobertura poblacional del SNS permite cierta equivalencia entre población censal y población asegurada, existe un desajuste con las personas aseguradas por mutualidades públicas (básicamente, MUFACE, MUGEJU e ISFAS) que quedan incluidos en el denominador censal, pero sus casos sólo se recogen en el numerador si fueron ingresados en hospitales del SNS. Si las personas aseguradas en dichos esquemas, con condiciones como las que se estudian en este Atlas, tuviesen preferencia por la atención en proveedores privados, se subestimarían las hospitalizaciones en las áreas con mayor número de beneficiarios de las citadas mutualidades.
¿De dónde proceden los datos para el análisis?
Los datos analizados proceden del registro administrativo de la información mínima básica del conjunto de altas hospitalarias cedidos por cada una de las consejerías de salud de las 17 comunidades autónomas, a través de su participación en el consorcio Atlas VPM, mediante el establecimiento de acuerdos bilaterales con el Instituto Aragonés de Ciencias de la Salud.
La participación de las consejerías de sanidad de los organismos autónomos en el consorcio Atlas VPM se establece mediante acuerdos bilaterales entre éstas y el Instituto Aragonés de Ciencias de la Salud. En estos acuerdos se fijan los términos de utilización de los conjuntos de datos regionales para los fines de investigación en políticas y servicios de salud propósito del Atlas VPM y el marco de desarrollo de los mismos.
Estos acuerdos permiten a Atlas VPM disponer de información actualizada sobre la actividad hospitalaria financiada públicamente por el Sistema Nacional de Salud en las 17 Comunidades Autónomas desde 2002 hasta 2018 (último año disponible), y proveer a su vez de información agregada sobre el rendimiento del sistema sanitario en términos de indicadores de actividad, calidad, seguridad y desempeño que se publican en forma de los Atlas de Variaciones temáticos.
Por otro lado, Atlas VPM trabaja a partir de los datos cedidos en interés de la mejora de los métodos de análisis evaluativo, la selección de comparadores a nivel nacional, y de la calidad de la información produciendo trabajos y desarrollos de interés para las Comunidades Autónomas en forma de informes específicos, métodos o desarrollos de programas y nuevas herramientas analíticas o formatos de visualización de datos.
¿Cómo se hace el análisis por área sanitaria o zona básica de salud?
La asignación de casos a cada área geográfica es uno de los aspectos esenciales en el análisis de VPM, ya que los episodios se contabilizan en el área y/o zona básica de residencia y, por tanto, se computan con independencia del hospital donde se produce el ingreso.
La asignación de casos a cada área geográfica es uno de los aspectos esenciales en el análisis de VPM, ya que los episodios se contabilizan en el área y/o zona básica de residencia y, por tanto, se computan con independencia del lugar, área o comunidad autónoma de hospitalización. En este sentido, el análisis realizado compara la experiencia de hospitalización de las poblaciones que residen en diferentes territorios antes que las pautas de ingreso utilizadas por los hospitales, aunque obviamente unas y otras están muy relacionadas. Los residentes en otros países se excluyen de estos análisis.
Por otra parte, la calidad de la codificación del municipio –o del distrito postal, según el caso- puede diferir entre hospitales, con casos en que el campo de registro de la residencia está incompleto. Esta situación ha obligado a la utilización de normas de asignación de casos, consistentes en:
— Los casos con código de residencia completo se asignan al área sanitaria que incluye el correspondiente municipio o código postal.
— Los casos con código de residencia incompleto pero que registran los dígitos de provincia del correspondiente código de INE o Postal, se reasignan al área del hospital donde se realizó el ingreso siempre que esta pertenezca a la provincia identificada en el citado código incompleto.
— Los casos con código de residencia incompleto en que la provincia identificada no coincide con la del hospital de ingreso se excluyen.
Esta normalización en la asignación ha conseguido que generalmente más del 98% de los casos sean asignados.
¿Cómo se calcula una estandarizada por sexo y edad para cada área geográfica?
Las tasas crudas por área representan el número de altas generadas (numerador de la tasa) en relación a la población registrada en el periodo (denominador) en esa área.
Las tasas estandarizadas por edad y sexo representarían la tasa que tendría un área si tuviera una población con la misma distribución por sexo y tramo etario que la población de referencia elegida, habitualmente, la población española registrada en el censo del momento.
La edad y el sexo son dos variables determinantes de la morbilidad, por lo que las diferencias en su distribución de la población de las diferentes áreas justificarían la variabilidad en las tasas de intervenciones. Para controlar este efecto se calculan las tasas específicas que presentan los grupos de edad y sexo de las diversas áreas y/o zonas básicas. A continuación, se calculan las tasas estandarizadas por edad y sexo, empleando como población de referencia la población española registrada en el censo durante el periodo de estudio. Estas tasas estandarizadas pueden no coincidir con las tasas crudas ya que representan las tasas que tendrían las diversas áreas y/o zonas básicas si todas tuvieran una población con la distribución de edad y sexo de la población de referencia.
Desde la perspectiva del Análisis de Variaciones de la Práctica Médica, estandarizar por dos variables, edad y sexo, que tienen tanta importancia en la carga de enfermedad y muerte de las poblaciones, permite comparar las áreas sanitarias descartando que sea la diferente epidemiología de las poblaciones estudiadas la causa de dicha variación.
Una vez calculadas, las tasas estandarizadas del total de áreas sanitarias o zonas básicas de salud se distribuyen en quintiles y se representan en los mapas utilizando gradientes del color, correspondiendo los tonos más oscuros con las tasas más altas. En la leyenda de cada mapa se indica el rango de valores de las tasas que abarca cada quintil (Figura 1).
Figura 1. Mapa de tasas estandarizadas de hospitalizaciones potencialmente evitables por zona básica de salud (www.cienciadedatosysalud.org/atlas/hpe-zbs)
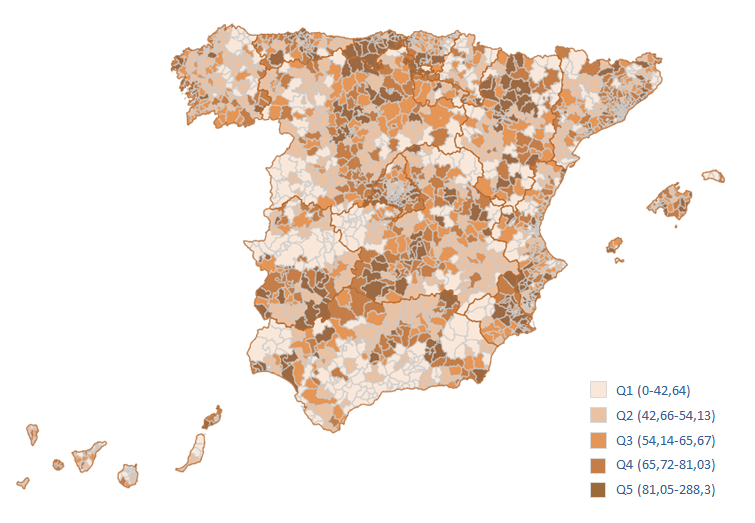
Figura 1. Métodos
¿Qué es y cómo se calcula una razón de utilización estandarizada para cada área geográfica?
Riesgo de hospitalización o de que se realice un procedimiento/intervención mayor o menor a lo esperado. Para ello se requiere estimar los casos esperados de cada área y contrastarla, con el número de casos observados. Esto permite evaluar si el comportamiento de una unidad de análisis es diferente del esperado.
La estimación de si el riesgo de hospitalización o de someterse un procedimiento es mayor o menor a lo esperado se realiza mediante la razón entre casos observados y esperados. Para ellos se requiere estimar los casos esperados de cada área y contrastarla, con el número de casos observados.
Los métodos para el cálculo de la razón de hospitalización estandarizada dependen del método de cálculo de los casos esperados. El cálculo de los mismos puede realizarse siguiendo diversas metodologías.
Razón de hospitalización estandarizada (RHE) calculada mediante estandarización indirecta. Los casos esperados se obtienen aplicando unas tasas de referencia (tasas específicas por grupo de edad y género referidas al conjunto de las 17 Comunidades Autónomas) a los efectivos poblacionales equivalentes de cada área. Sería, por tanto, la utilización esperada si las subpoblaciones de los distintos territorios homogeneizaran sus niveles de hospitalización de acuerdo a las tasas globales. Este método no permite la comparación entre áreas y/o zonas básicas, pues no pueden obviarse las diferencias en estructura de edad y sexo entre ellas. Por contra, permite la comparación de cada una con un patrón global, y puede interpretarse como un “riesgo relativo”.
El valor central RHE es la unidad, en cuyo caso el área responde al patrón medio de utilización pues se observa lo que sería esperable. El índice se mueve en dos direcciones: de 1 a infinito (sobreutilización respecto a la media) y de 1 a 0 (infrautilización). Se requiere, por tanto, una transformación de esta última escala (cálculo del inverso: 1/x) para alcanzar una expresión común del tipo “porcentaje de sobre o infrautilización”. En este sentido, poblaciones con RHE de 1,50 o 0,67, reciben un 50% de intervenciones por encima o por debajo, respectivamente, de lo que cabría esperar a partir del patrón medio de utilización. También para este estadístico se calcularon los intervalos de confianza del 95% que permiten valorar si dichas razones son o no estadísticamente significativas.
Razón de Hospitalización Estandarizada (RHE) estimada mediante metodología bayesiana
Utilizando la metodología bayesiana de Besag-York-Mollie, se calcula la probabilidad de que la RHE exceda estadísticamente el valor 1 (mayor riesgo del esperado) o presente un valor estadísticamente inferior a 1 (menor riesgo del esperado).
Para la representación (figura 2), se utilizan dos puntos de corte –una probabilidad entre 0,8 y 0,9, probabilidad alta de que el riesgo de que ocurra el evento sea mayor (o menor) del esperado; y, una probabilidad mayor de 0,9, probabilidad muy alta de que el riesgo de que ocurra sea mayor (o menor) del esperado. Los colores fucsias muestran aquellas áreas sanitarias o zonas básicas de salud con RHE mayor del esperado; mientras que los marrones representan
áreas con riesgo menor del esperado. La intensidad de color determina la probabilidad alta o muy alta de que la observación sea cierta. El color amarillo pálido representa áreas o zonas básicas con una probabilidad baja (menor a 0,8) de que los sucesos observados y esperados sean distintas.
Figura 2. Mapa de riesgo de hospitalización potencialmente evitable a nivel de zona básica de salud (www.cienciadedatosysalud.org/atlas/hpe-zbs)
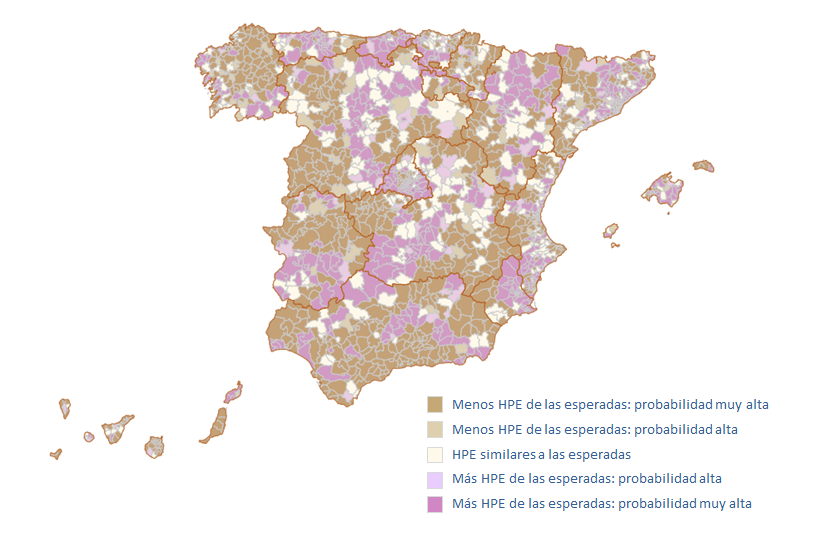
Figura 2. Mapa de riesgo de hospitalización potencialmente evitable a nivel de zona básica de salud (www.cienciadedatosysalud.org/atlas/hpe-zbs)
¿Cómo se realiza el análisis de desempeño hospitalario?
Para determinados indicadores de calidad y seguridad hospitalaria, el desempeño de los hospitales del SNS se realiza calculando el riesgo de que ocurra un determinado evento mediante el cociente entre el número observado de casos ocurridos en el hospital respecto al número de casos esperados, según la casuística de los episodios atendidos. Esto se realiza mediante la razón de hospitalización estandarizada (RHE).
¿Cómo se calcula una razón de hospitalización ajustada para cada hospital?
Para la obtención de los “valores esperados” y dada la naturaleza jerárquica de los datos (episodios agrupados por hospitales) se especifican modelos de regresión logística multinivel. Los indicadores de calidad y seguridad analizados tienen como variable dependiente la ocurrencia o no del evento y como variables explicativas, dependiendo del indicador estudiado se añadirán aquellas que se consideren más relevantes en cada caso. De manera general se suelen utilizar la edad, el sexo, y el conjunto de condiciones clínicas de Elixhauser (comorbilidades) que resulten estadísticamente significativas.
El contraste de significación estadística para los valores de las RHE se realiza teniendo en cuenta el volumen de pacientes a riesgo atendido en cada hospital, que representado gráficamente equivaldría al tradicional gráfico de embudo o funnel plot (figura 3).
Figura 3. Distribución de la Standardised Mortality Rate[1] por infarto agudo de miocardio en los hospitales de complejidad atendida alta analizados en el año 2015
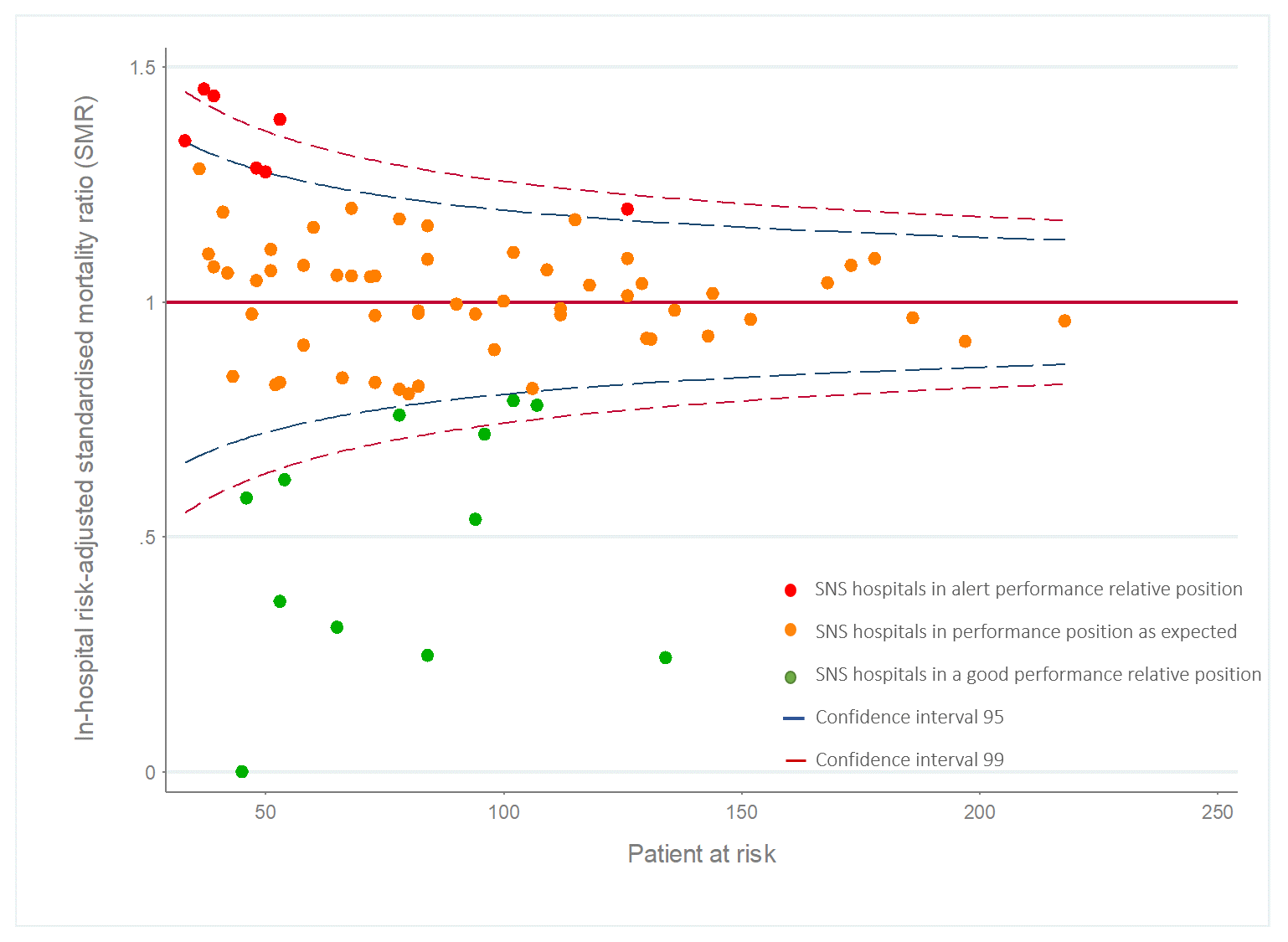
Figura 3. Distribución de la Standardised Mortality Rate por infarto agudo de miocardio en los hospitales de alta complejidad atendida analizados en el año 2015
[1] La tasa estandarizada de mortalidad (Standardised Mortality Rate, SMR), podría considerarse un subtipo de RHE en el que el resultado medido es la mortalidad asociada a un diagnóstico o procedimiento).
En el caso de eventos que no son deseables que ocurran (i.e. mortalidad), si la RHE de un hospital es significativamente inferior al benchmark o umbral de referencia, indicaría que los sucesos observados son significativamente inferiores a los esperados. Los hospitales con riesgos inferiores se consideran Hospitales Excelentes o de referencia. Si la RHE no es significativamente distinta del benchmark, los hospitales se considerarán como Hospitales Aceptables. Por último, si la RHE es superior al benchmark, es decir el riesgo observado es significativamente superior al esperado, los centros se considerarán Hospitales Mejorables.
En el mapa donde están geolocalizados los hospitales del SNS (Figura 4), éstos se representan por un círculo cuyo tamaño es proporcional a la población a riesgo de cada indicador, (i.e. la población ingresada de urgencia por infarto en el caso de los indicadores de mortalidad por IAM). El color del círculo representa la posición relativa del riesgo en cada hospital, determinado por la RHE, es decir, en qué medida la relación entre los valores observados y esperados del hospital, difieren significativamente del umbral de referencia aquel en el que el valor observado y esperado coinciden.
Figura 4. Mapa de mortalidad intrahospitalaria por enfermedad isquémica coronaria en hospitales con alta complejidad atendida
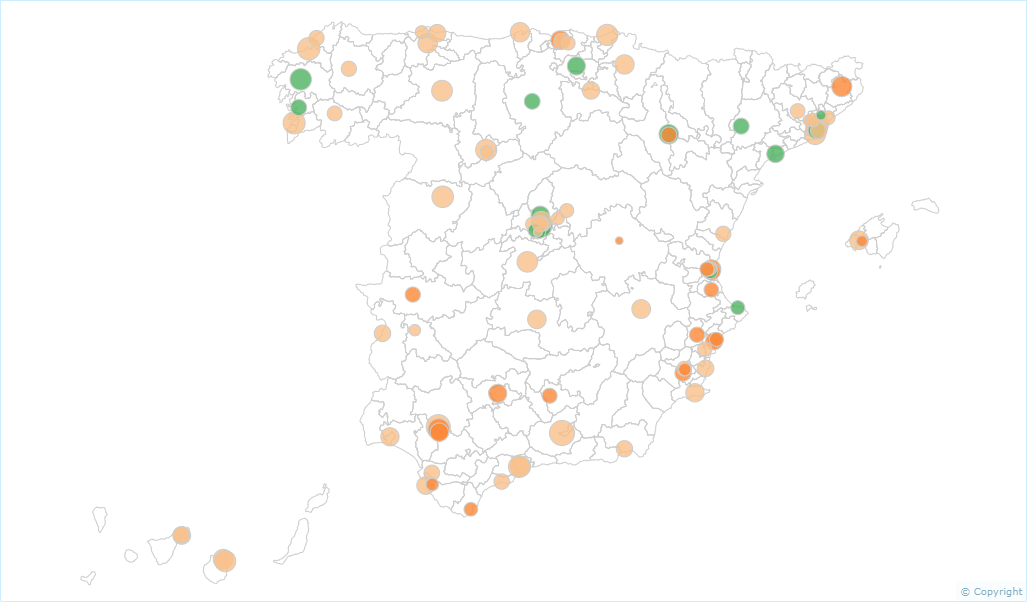
Mapa de mortalidad intrahospitalaria por infarto agudo de miocardio en hospitales de alta complejidad atendida en 2015
¿Por qué se hace el ajuste de riesgo?
Para identificar y homogeneizar diferencias en los pacientes (población de referencia / población atendida) que pueden afectar a la comparación de un resultado sanitario de interés.
En los estudios geográficos, las diferencias en las poblaciones se han “tratado” (homogeneizado, ajustado, controlado) mediante estandarización directa e indirecta, utilizando la edad y el sexo, y asumiendo que éstos son proxy suficiente de las diferencias epidemiológicas de las poblaciones. El análisis cambia cuando el sujeto de estudio son los pacientes atendidos en un determinado centro sanitario (hospitales en la casuística que maneja Atlas VPM). Aquí, la edad y el sexo son insuficientes y se precisa observar más variables: presencia de comorbilidad, severidad de la enfermedad de base, etc. Son múltiples los mecanismos para controlar las diferencias entre proveedores, y se puede hacer ex ante, seleccionando pacientes parecidos, por ejemplo; o ex post, utilizando lo que se denomina “ajuste de riesgos”.
¿Cómo se clasifican los proveedores sanitarios (hospitales)? ¿Por qué es necesaria su clasificación?
En función de los indicadores analizados, se realiza una estratificación de los hospitales teniendo en cuenta las características organizativas de los mismos y el nivel de complejidad atendida. La finalidad de esta clasificación es poder comparar los resultados sanitarios en términos de desempeño de aquellos hospitales que son semejantes entre sí.
Con el fin de asegurar la comparabilidad entre hospitales y evitar ruido estadístico en la modelización de resultados, en los análisis hospitalarios solo se incluyen aquellos hospitales que presentaron al menos 30 casos de la población a riesgo de cada indicador analizado (p.ej. aquellos que realizaron un número superior de 30 intervenciones, en caso de los indicadores de procedimientos). Este hecho puede hacer que en el caso de los análisis de serie temporal el número de hospitales analizados varíe ligeramente entre los distintos años de la serie.
¿Cómo se analiza la evolución de las áreas o de los hospitales en el tiempo?
Evolución temporal. En el caso de analizar la evolución de un indicador a lo largo del tiempo, se calculan las tasas estandarizadas por edad y sexo mediante el método directo utilizando la población del primer año de la serie como referencia.
La evolución de los indicadores puede compararse con la evolución de un valor de referencia (benchmark) a lo largo de los años. Esta referencia puede ser un valor “promedio” (p.ej. la mediana nacional o tasa media) o un umbral que marca un máximo o mínimo deseable (p.ej. p25 en el Atlas de procedimientos de bajo valor).
En algunos casos también puede ser de interés realizar el análisis dinámico sobre la evolución mensual (o en su defecto, la periodicidad más fragmentada que la tipología de los datos admitan) de cada indicador haciendo uso de modelos generales aditivos multinivel (GAM) que permiten capturar aspectos de la evolución temporal como posibles patrones de comportamiento estacionales y otros efectos tipo calendario, con el objetivo final de proyectar el desempeño sanitario esperable en los 12 o 24 meses posteriores.
¿Qué otros análisis se hacen en AtlasVPM?
OTRAS REPRESENTACIONES GRÁFICAS
– Gráficos violín. Estos gráficos permiten visualizar la distribución de un conjunto tasas o valores utilizando para su representación en forma de violín una función de densidad de Kernel. En la caja central, el círculo representa la mediana de los valores, la caja el rango intercuartílico y las “rayas” el percentil 95 y 5.
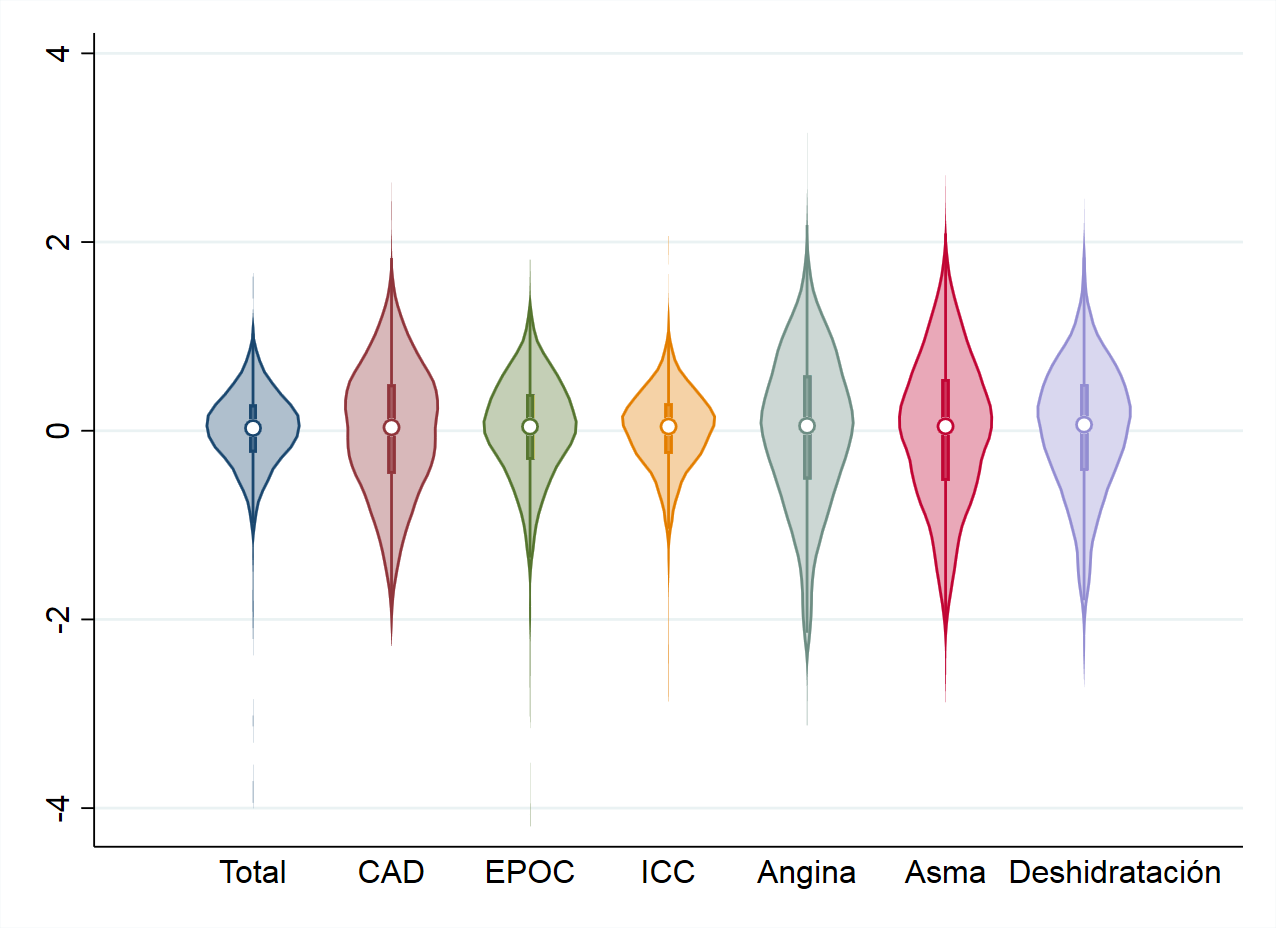
Figura 5.
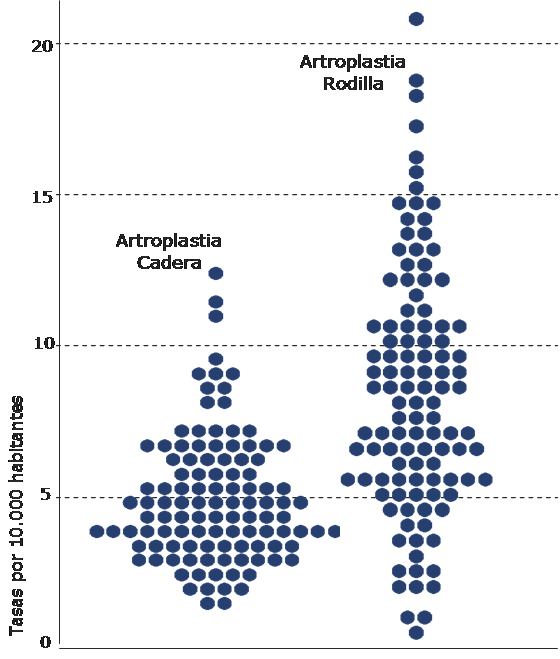
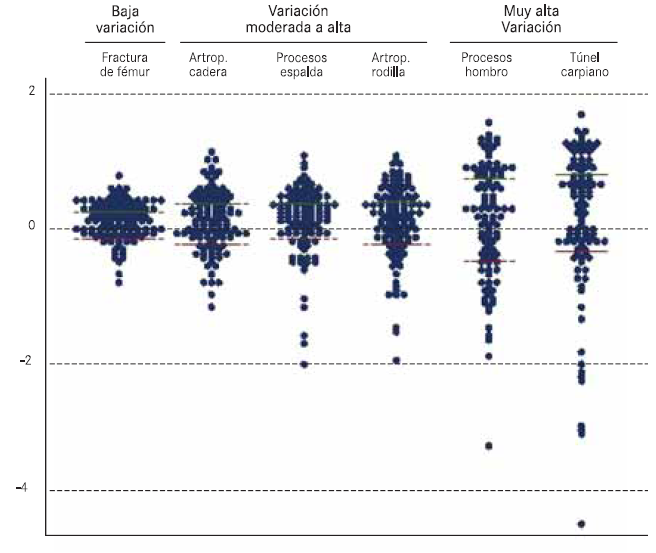
– Gráficos de puntos (dotplot). Cada punto representa el valor de una tasa en un área de salud. Las áreas con tasas similares se representan al mismo nivel, con lo que los gráficos de puntos adoptan una imagen romboidal, que será más simétrica cuanto más se parezca la distribución estudiada a una normal.
Cuando se representan distintos indicadores cuyas tasas oscilan en rangos muy diferentes, los procedimientos con menores tasas se agrupan en la base de la gráfica sugiriendo menor variación. En estos casos se recurre la representación de la tasa en escala logarítmica, que permite obviar este efecto al mostrar todos los valores en la misma escala. Adicionalmente, a los logaritmos de las tasas se les resta el logaritmo de la media de las áreas, de modo que la escala se distribuye en una media común de valor 0 para todas las áreas analizadas.
– Gráficos de burbujas. Estos gráficos son un caso particular del gráfico de puntos en el que cada burbuja representa un área sanitaria y su tamaño es proporcional al número de habitantes de la misma. Las burbujas se agrupan por CCAA en distintas columnas. En Atlas VPM este gráfico se utiliza para mostrar la variación de las áreas sanitarias dentro de cada Comunidad Autónoma, y comparar áreas de distintas Comunidades Autónomas entre sí. Este gráfico, a diferencia de los anteriores, se utiliza sólo para representar un procedimiento.
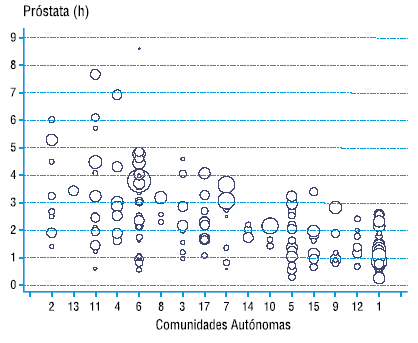
Figura 7.
¿Cómo puedo interpretar los estadísticos de variación?
– Razón de variación
La razón de variación (RV) es el cociente entre el valor más alto y el más bajo de las tasas estandarizadas para el conjunto de las áreas y/o zonas básicas estudiadas.
Es muy utilizado por su sencillez y por ser muy intuitivo. Sin embargo, presenta importantes limitaciones ya que es muy sensible a las tasas bajas, a las diferencias en el tamaño de la población entre áreas, a los reingresos y a los valores extremos. Su poder estadístico es muy bajo y, si algún área no tiene sucesos -usual en estudios en pequeñas áreas- ofrece valores incongruentes. Actualmente, es usual sustituirlo por la razón de variación entre las áreas en los percentiles 95 y 5 (RV95-5) que reduce el efecto de los valores extremos, y acompañarlo de la razón de variación entre los percentiles 75 y 25 (RV75-25) que ofrece una idea de la variabilidad en el 50% central de las observaciones.
– Coeficiente de variación no ponderado (Unweighted Coefficient of Variation, CVu o CV)
Es el cociente entre la desviación estándar y la media. El CV expresa el valor de la desviación estándar en unidades de media con la ventaja, frente a la desviación estándar, de no depender de las unidades de medida. Es interpretable en términos de variación relativa (más variabilidad a mayor valor del coeficiente).
– Coeficiente de variación ponderado (Weighted Coefficient of Variation, CVw)
Es el cociente entre la desviación estándar entre áreas y la media entre áreas, ponderadas por el tamaño de cada área. El CVw es similar al CVu, si bien otorga mayor peso a las áreas con mayor número de habitantes y soporta mejor que éste la presencia de áreas con tamaños poblacionales diferentes. Es uno de los estadísticos de elección cuando el tamaño de las áreas es muy diferente.
-Componente sistemático de la variación (Systematic Component of Variation, SCV)
Mide la variación de la desviación entre la tasa observada y esperada, expresada como porcentaje de la tasa esperada. Es una medida derivada a partir de un modelo que reconoce dos fuentes de variación: variación sistemática (diferencia entre áreas) y variación aleatoria (diferencia dentro de cada área). Mide la variación de la desviación entre la tasa observada y esperada, expresada como porcentaje de la tasa esperada. A mayor SCV mayor variación sistemática (no esperable por azar).
-Estadístico Empírico de Bayes (Empirical Bayes statistic, EB)
La RHE, es un estimador del “riesgo relativo” de cada área, es decir, del riesgo de utilización en relación con el grupo considerado de referencia y depende en gran medida del tamaño poblacional (su varianza es inversamente proporcional a los casos esperados). En este sentido, las RHE extremas y, por tanto, dominantes en el patrón geográfico aparente, son las estimaciones menos precisas procedentes de áreas con pocos casos. Por otro lado, la variabilidad de los casos observados suele ser bastante mayor que la esperada en una distribución de Poisson (extravariablidad).
Con el fin de solucionar estos problemas se han propuesto varias alternativas. Partiendo del supuesto de que los casos observados se distribuyen como una distribución de Poisson, el método empírico bayesiano asume además que la RHE también es una variable aleatoria que, en nuestro caso, sigue una distribución log-normal [log(ri) ~ N(m, s2)]. Este modelo se conoce como un modelo mixto Poisson log-normal. El estadístico EB aquí empleado es la estimación de la varianza de la distribución log-normal que mejor se ajusta (verosimilitud) al patrón geográfico de la RIE, teniendo en consideración la precisión de sus estimaciones. Se obtiene por máxima verosimilitud no completa (Penalized Quasi Likelihood method). Pese a que es poco intuitivo (debe interpretarse en términos de variación relativa), en los estudios empíricos, el EB se comporta como un estadístico con gran poder para detectar variabilidad al tiempo que es el más estable a la variabilidad entre áreas y a las pequeñas frecuencias.